Last Updated on January 29, 2020 by Mathew Diekhake
There are plenty of advantages of not using databases where they are not strictly needed, but far from everyone already knows what they are all about in the technology world. You might have heard of the word “Database.” Of course, you have. People everywhere are using it to maintain their blogs and websites.
But have you ever considered looking into the security flaws the database may possess if not properly configured and may leave your blog backdoored and vulnerable to malicious attacks and operations? So should you jump into the bandwagon of database structured websites and blogs? Let’s see.
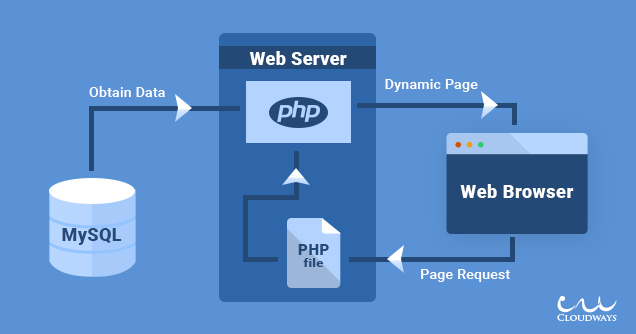
An average server setup of the hosted website developer includes:
- Web space to host files
- FTP to transfer files to web space
- Apache or similar with PHP as web server
Your part is to upload your site or the system of your choice. All the known systems (most of them) use a shitload of PHP resources to handle the logic and be as responsive to the user as possible but need to store the data somewhere. Databases e.g. MySQL are most convenient here. They are a service like an apache, only with a different protocol and often only open to local connections to increase security.
Well, the PHP system has to get the data somehow. So the database has at minimum one admin user and password and one with restricted rights (e.g. cannot drop tables or so) for the system. In turn, most users don’t know coding, and for the most that do, sniffing inside the system is one hell of a nightmare and also not a good idea (if you run in production mode anyhow).
Conventional CMS (content management systems) have a complicated directory structure and use databases for everything that is variable and fully userrelated. Some famous examples include WordPress, Joomla, Drupal, ExpressionEngine.
The biggest problem with databases is they require maintenance and proper techniques to safeguard them from various attacks and data leaking. It may even jeopardize an institution if not taken care of. Databases always need a bunch of security concerns such as:
● Database access (not accessible from the internet, if possible only locally on the server)
● Database communication, e.g. SQL injections: I could be a hacker and know how things with writing a value from a text field to the database are done. I know they are inserted in SQL queries like so:
$sql = ‘INSERT INTO table_name (text_field01) VALUES (“‘.$value.'”);’; if ( $conn>query($sql) === TRUE) {
I could change my entry to end the current command and issue a second one, possibly deleting or exposing the whole database to me. This has to be prevented through prepared statements to lock the database onto specific commands before sending the actual values.
● Data concurrency and authentication: Databases are often prone to corruption and need a shitload of backups periodically.
● There might have been potential flaws or errors left while programming or designing the database that might lead to portholes in the database and make it extremely vulnerable for hackers to attack.
SQL injection is not the only type of harm, though. It might also be that for the server everything goes as it should, and the end user is the only victim, called XSS, or crosssite scripting. Imagine a social media site where the comments are saved and echoed back to everyone else. It is supposed to be text, but could be all sorts of letter combinations. If the server only inserts the string of every comment into the page, one could write HTML code that then is displayed. That gets dangerous when a script tag is placed, and the browser starts running foreign JavaScript code because (to the browser) it is a valid and indistinguishable part of the website. By stealing cookies, for example, one could obtain critical information about the victim. On a site like PayPal or Amazon, it is clear what identity theft would mean.
Of course, a database is advisable in almost any situations, but only almost: If its advantages only play a minor role in the context of your project, e.g. If no user interaction is required and you can code it might be better not to use a database at all, given that a lot of web designers find fiddling in the CMS to change one CSS line tiring. Also, you wouldn’t require a database if your dataset is trivial and does not need to be organized.
But when you do not use a database at all, you simply do not have any of these problems. When all you have is your FTP password (I haven’t heard of people saying we should worry about FTP exploits, else you can also use SFTP or SSH), there is no place for hackers to go except DDOS attacks.
CMS often target people that have no idea of coding (it is probably the reason they exist) but want to have a good looking website nonetheless, so they will try hard not to show them anything complicated. That makes it often more difficult for such people like me who say “oh this doesn’t fit, let’s just give it a margin: 0 auto; borderradius: 10px;real quick” to find the right place to set this.
In my opinion, optimizing a blog or website through code would not be difficult once you have learned how things such as PHP, HTML, and CSS work.
How to make a blog without a database
So we’ve seen that advantages of not having a database outweigh its presence generally for a blog or simple website where it isn’t much needed. So now we proceed onto creating a databaseless blog which is very easy if you know basic PHP and HTML.
We are going to presume a typical setup consisting of Apache, PHP and of course FTP access. Our primary goals are following things:
Maximum control as a web designer/developer and writing articles in raw HTML and CSS
Minimal effort when integrating articles with various advanced CMS functions such as overview, categories, posts view, search algorithm, etc.
To stay organized, we will put all our articles into an article directory with subdirectories named with the slugs of the articles. These will contain an info file, for the title, author, etc., and the content file. This way to display article content, we simply have to include the content.php file as follows:
When showing the overview, we just iterate over the article directory contents and include the info file:
But how to store the information so we can iterate through the articles like this? We might use a class:
class Article {
public $slug = ”;
public $title = “”;
public $author = “”;
public $published = 0;
public $description = “”;
public $categories = array();
public $preview = “”;
public $root = ”;
function __construct($slug=”, $root=”) {
$this->slug = $slug;
if ($root === ”) {
$root = ‘./article/’.$slug.’/’;
}
$this->root = $root;
}
}
and call $THIS = new Article(slug); on each iteration before including the info file containing:
This will overwrite the blank properties so that we can use them. Now our loop looks something like this:
}
?>
This pattern can be continued as seen on www.github.com/peternerlich/StaticBlogSystem, which is a system developed by my friend Peter Nerlich where these snippets were taken from in a simplified form and me.
The only problem left is searching. The mentioned GitHub repository features its very own search algorithm to compliment this database-free blogging system that searches through all titles, descriptions, and keywords collected into a single index file that points to the corresponding articles. The more matches, the higher the “fitness” or relevance of the result.
Bam….Problem Solved
Now we have a solid outline for a database-free and intuitive blog system which you can style to your desires. So what do you think of such kind of blog system? Let me know your opinions in the comments below!